|
Xianzhi Du I am a Principal Scientist at Apple AI/ML, working on LLM pre-train, mid-train, multimodal and MoE. The Apple Foundation Models we built power a wide range of Apple Intelligent features across Apple platforms. I was previously a Research Engineer at Google Brain and Google CoreML working on computer vision research and building TensorFlow official models. I also worked extensively on collaborating with Alphabet's teams, including Waymo, Google Cloud, Google Maps, Google Photos, Nest, X, to apply state-of-the-art research models to Alphabet's applications. I did my PhD at UMIACS, University of Maryland, College Park, where I was advised by Larry Davis and David Doermann. Last updated: 2025/06 Email / Google Scholar / LinkedIn / Twitter |

|
Research Highlights |
|
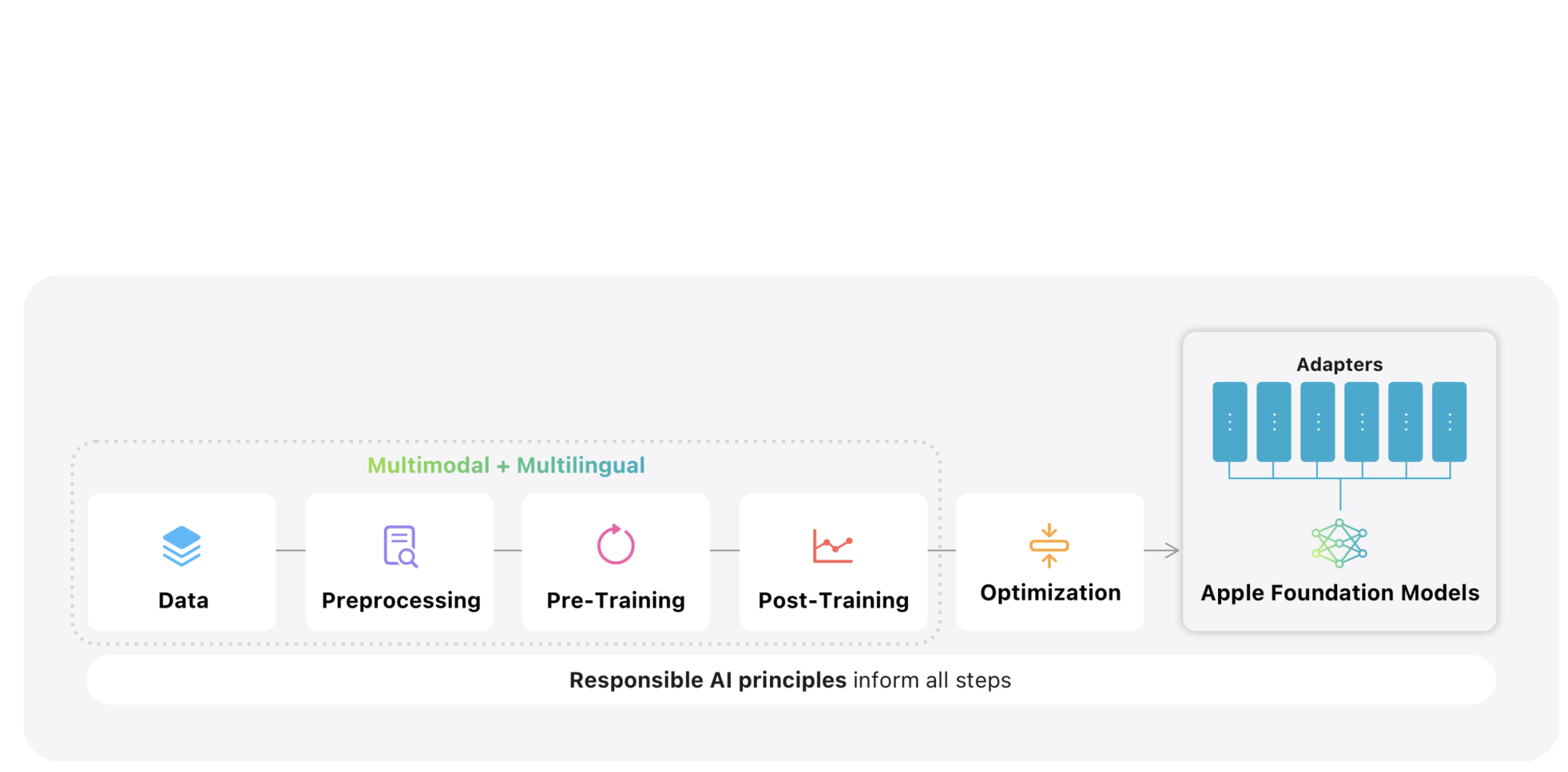
Apple Intelligence Foundation Language Models 2025
arXiv, 2025. Multimodal pre-train lead. blog post / Github 2025 updated version of Apple Intelligence Foundation models. Powering Apple Intelligence features . |
|
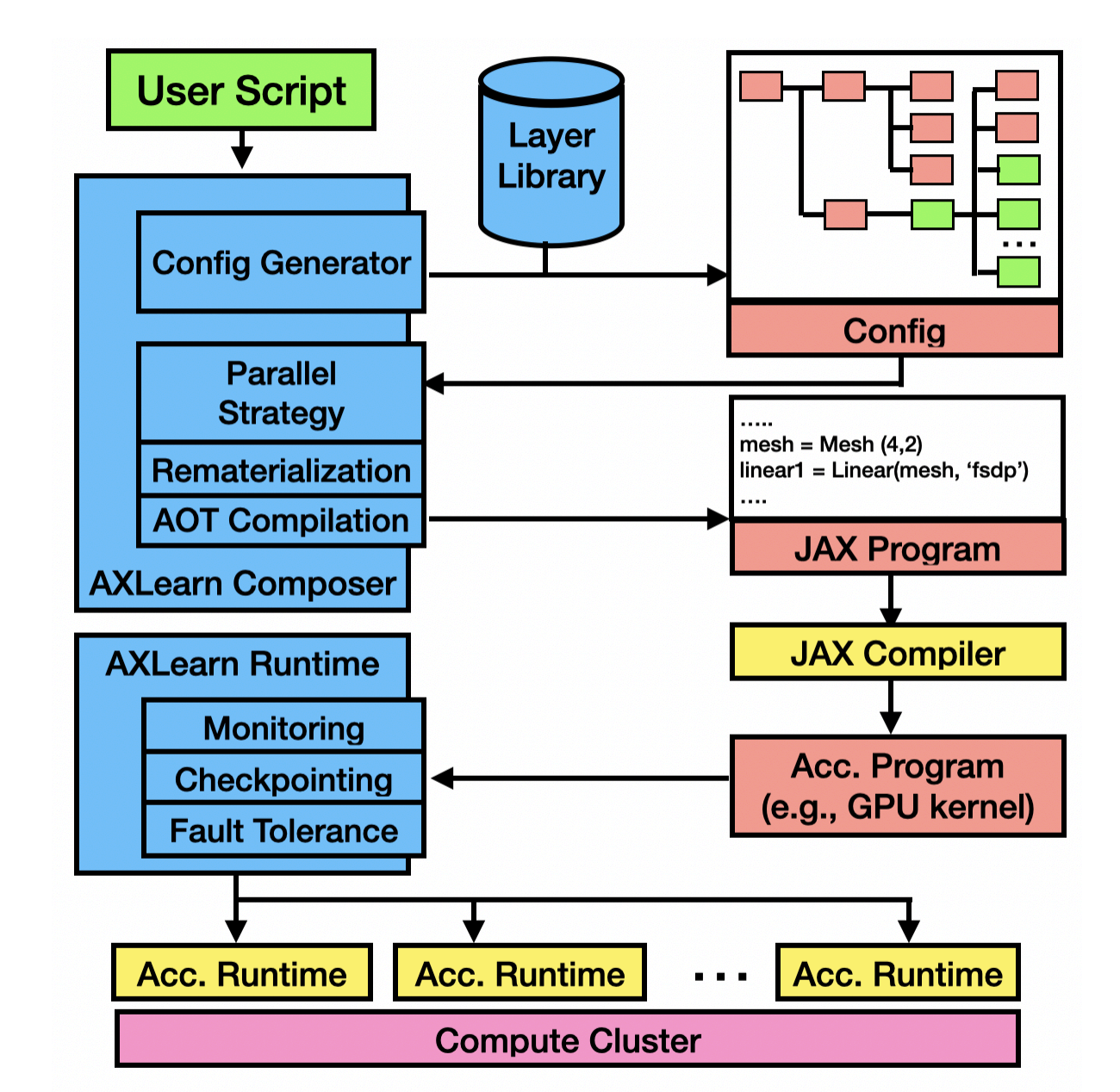
AXLearn: Modular Large Model Training on Heterogeneous Infrastructure
arXiv, 2025. Github A production deep learning system that facilitates scalable and high-performance training of large deep learning models . |
|
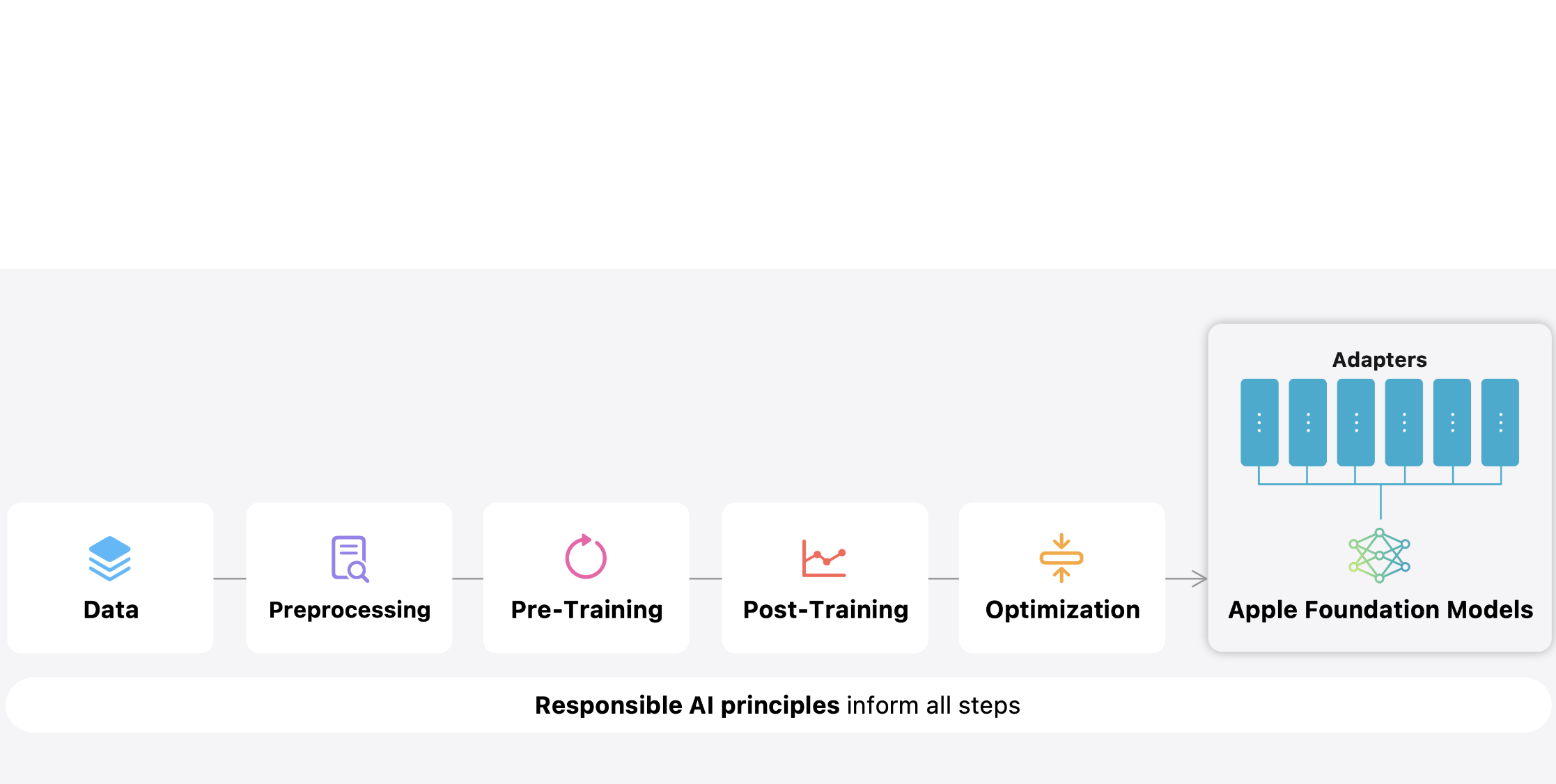
Apple Intelligence Foundation Language Models
arXiv, 2024 blog post / project page / Github Introduces Apple’s on-device and server foundation models. Announced at the 2024 Worldwide Developers Conference. |
|
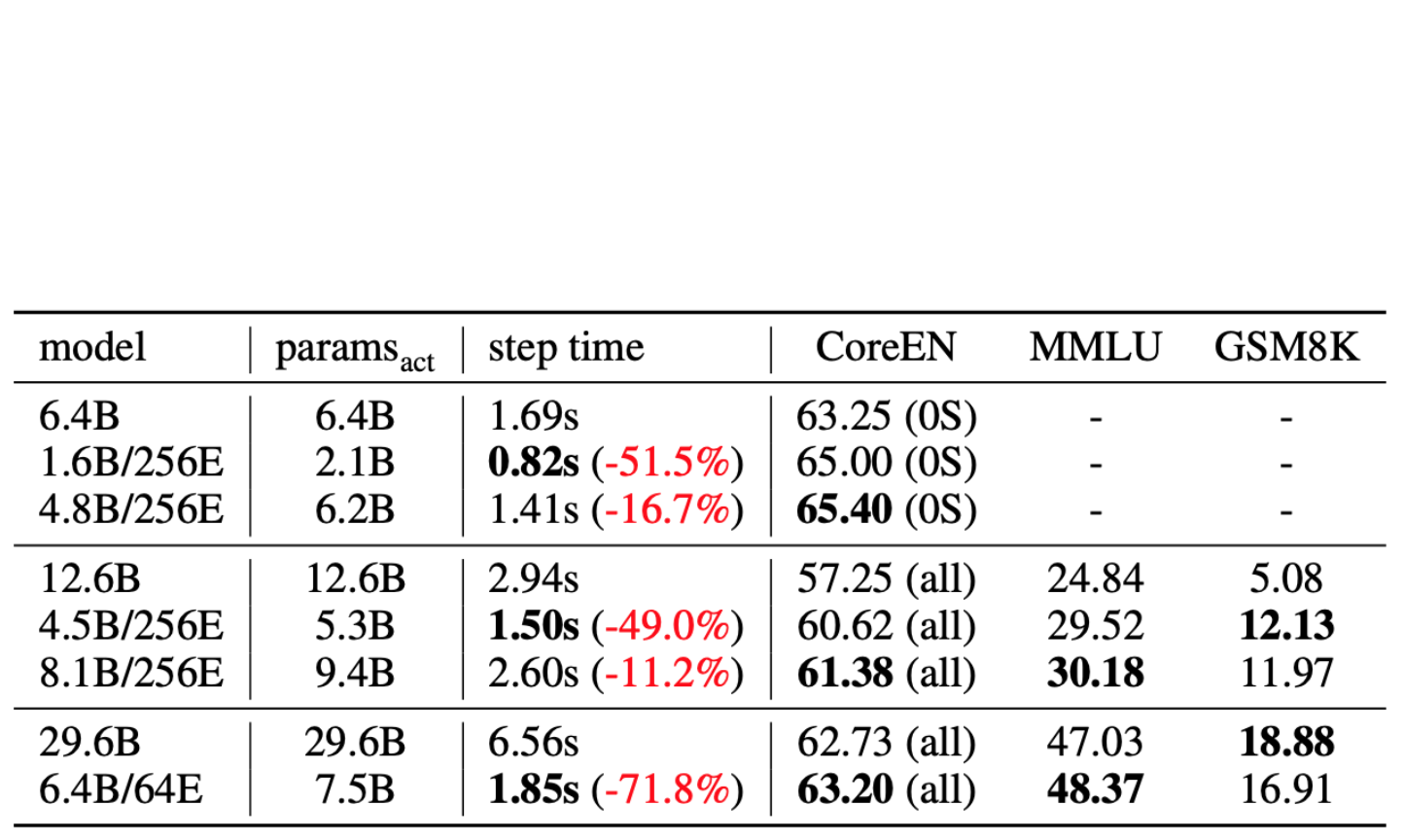
Revisiting MoE and Dense Speed-Accuracy Comparisons for LLM Training
arXiv, 2024 Github Compares MoE and dense LLMs by using step time to measure model speed and designing total train budget with Chinchilla compute-optimal setting. We show MoE consistently outperforms dense models at 6B, 13B and 30B. |
|
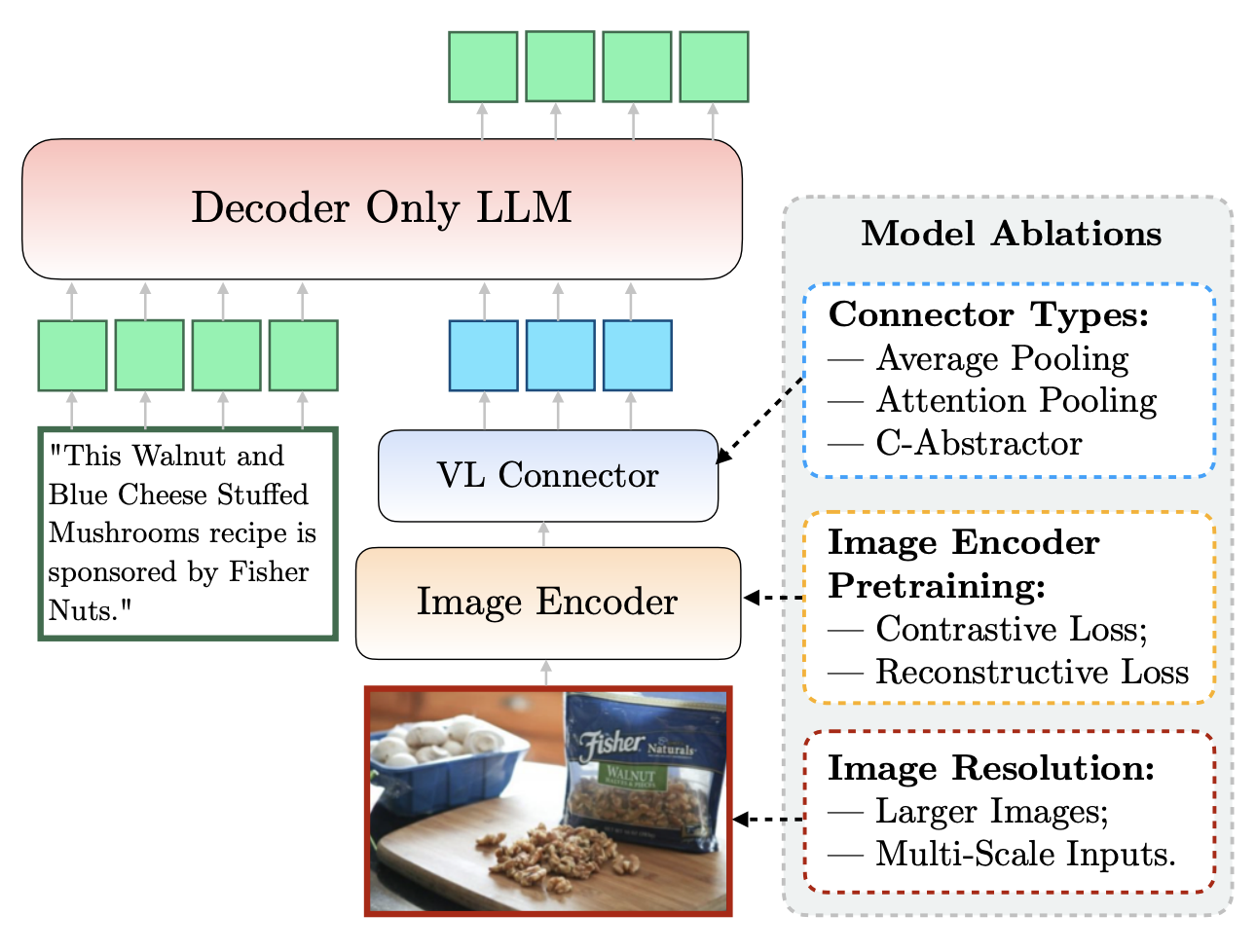
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
arXiv, 2024 project page / Github Builds high-performance MLLMs by identifying crucial architectural and data choices, leading to the creation of MM1 models, which excel in pre-training metrics and few-shot learning across various benchmarks. |
|
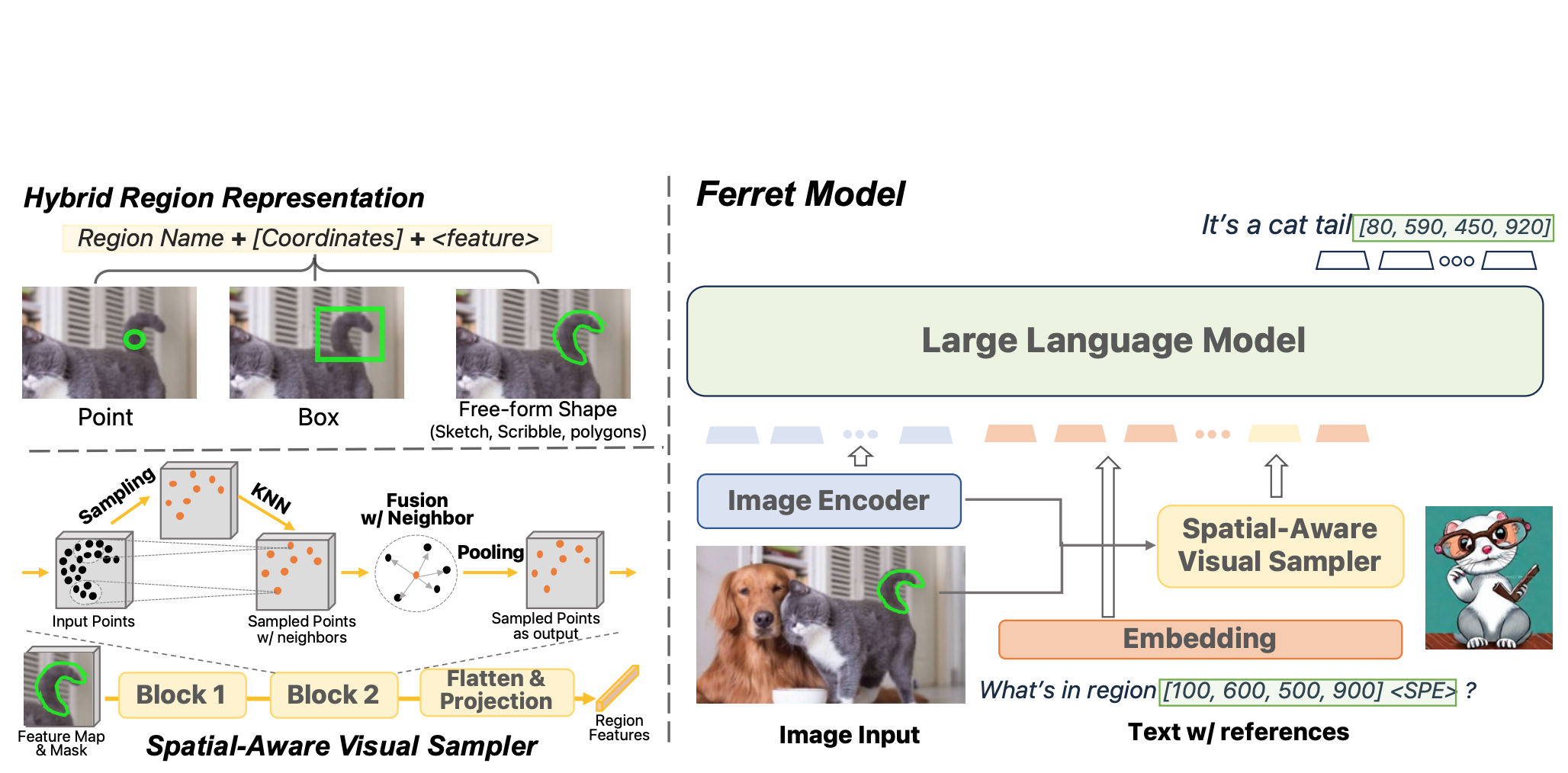
Ferret: Refer and ground anything anywhere at any granularity
ICLR, 2024 (Spotlight) project page / Github A novel MLLM that excels in fine-grained spatial understanding and grounding descriptions within images, using a hybrid region representation and a specialized dataset, demonstrating superior performance and reduced object hallucination. |
|
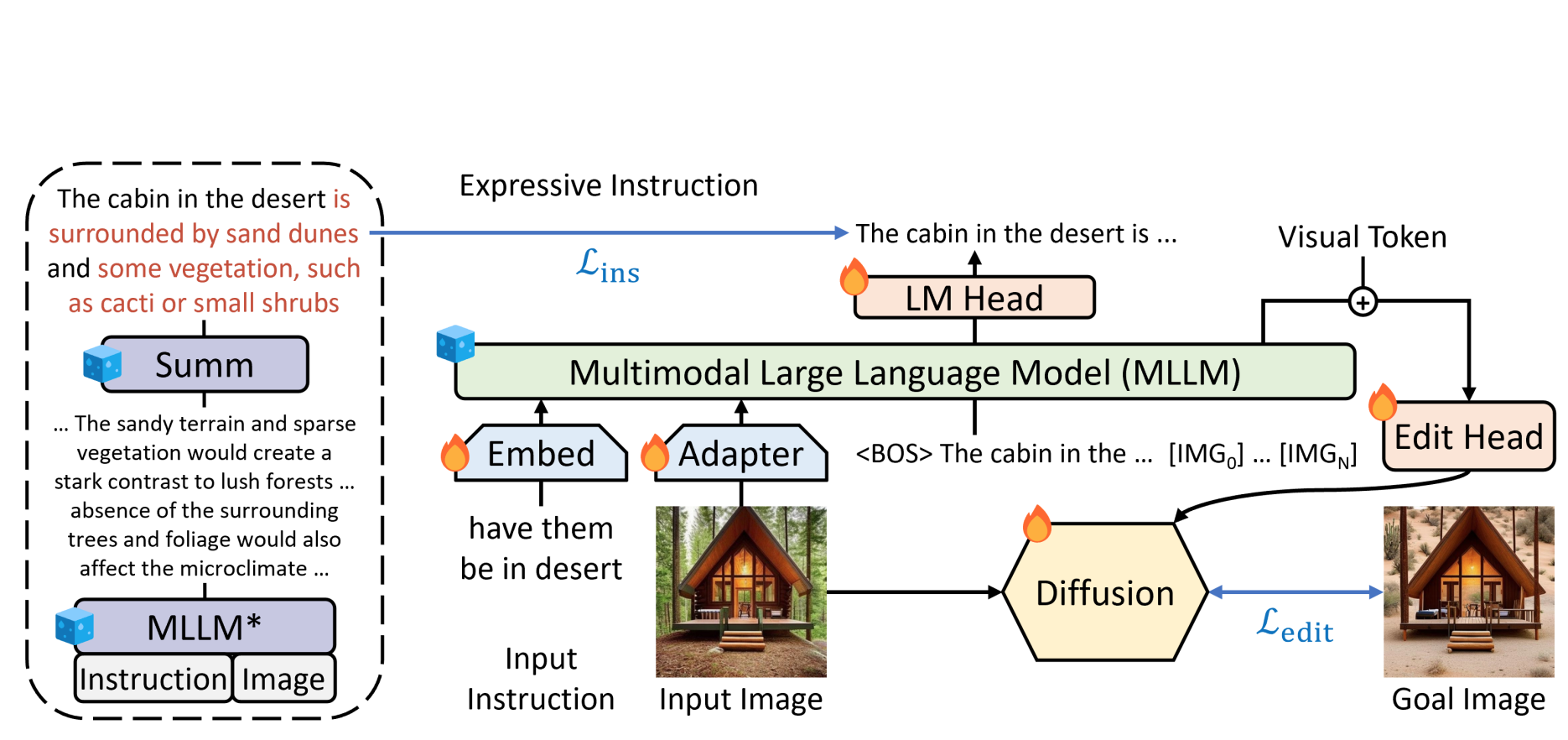
Guiding instruction-based image editing via multimodal large language models
ICLR, 2024 (Spotlight) project page / Github Leverages Multimodal LLMs to enhance instruction-based image editing, derive expressive instructions and provide explicit guidance. |
|
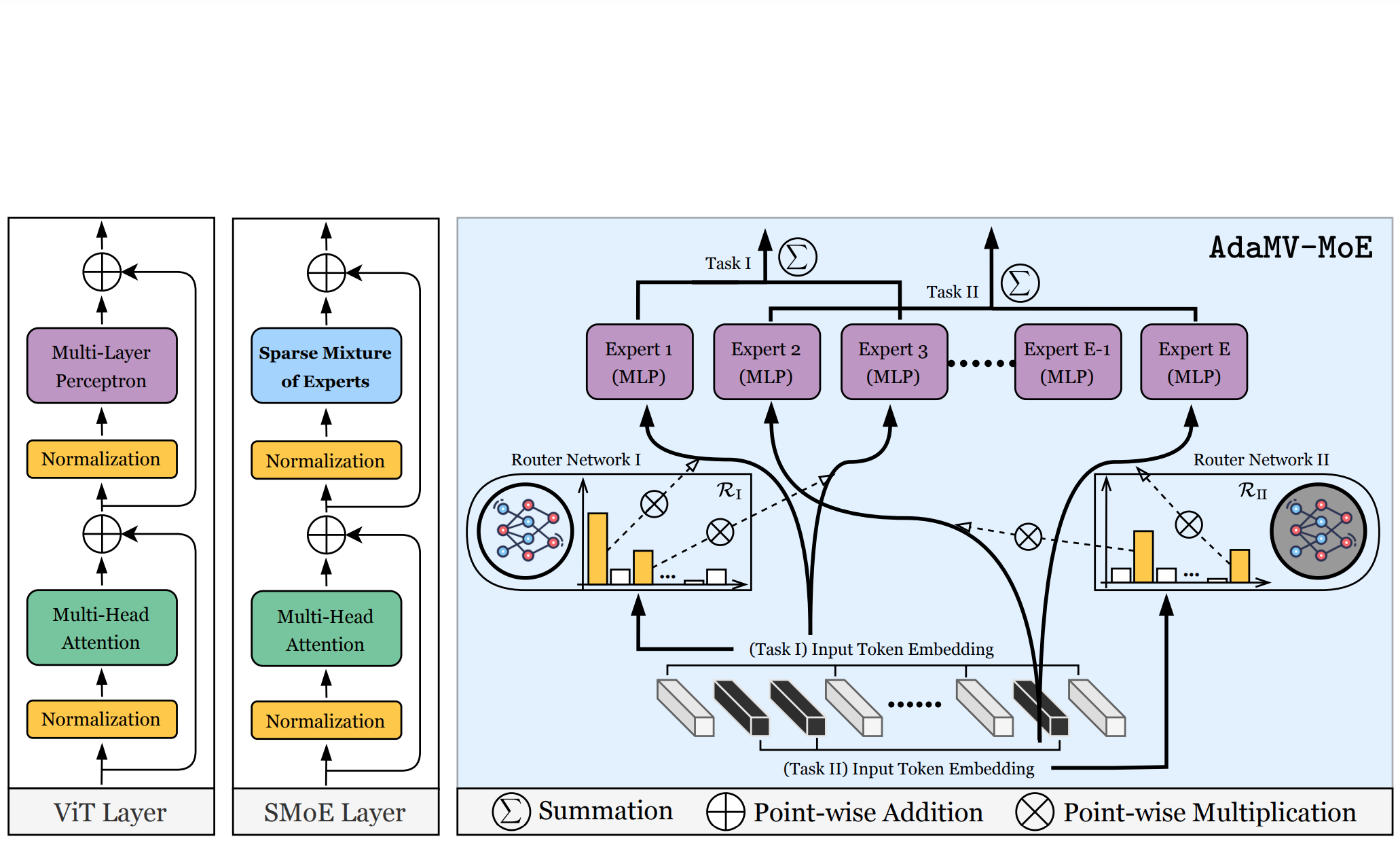
Adamv-moe: Adaptive multi-task vision mixture-of-experts
ICCV, 2023 Github An adaptive MoE framework that dynamically adjusts experts per task, enhancing multi-task vision recognition performance on ImageNet and COCO. |
|
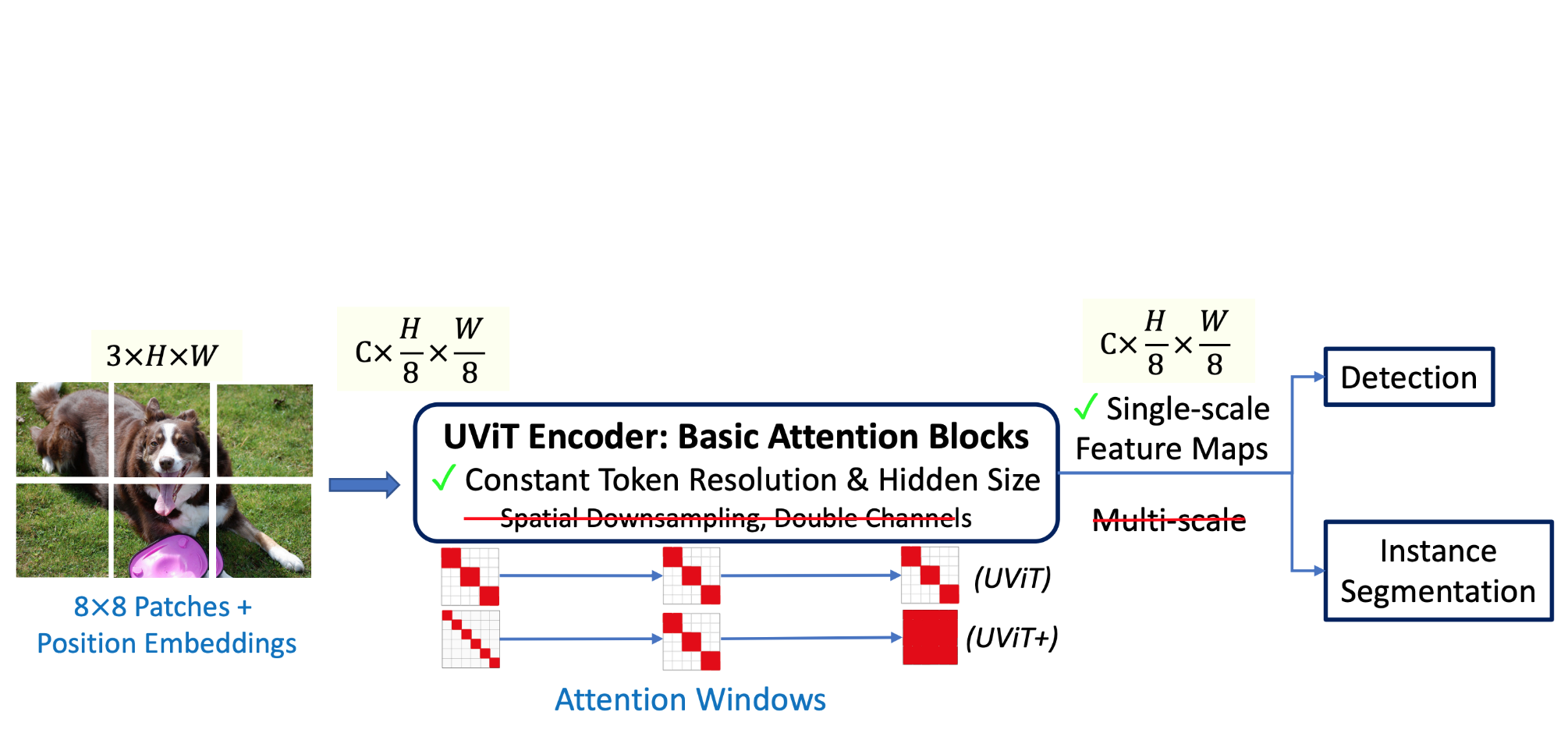
A Simple Single-Scale Vision Transformer for Object Detection and Instance Segmentation
ECCV, 2022 Github Designs a simple single-scale vision transformer architecture, achieves strong performance on object localization and instance segmentation tasks. |
|
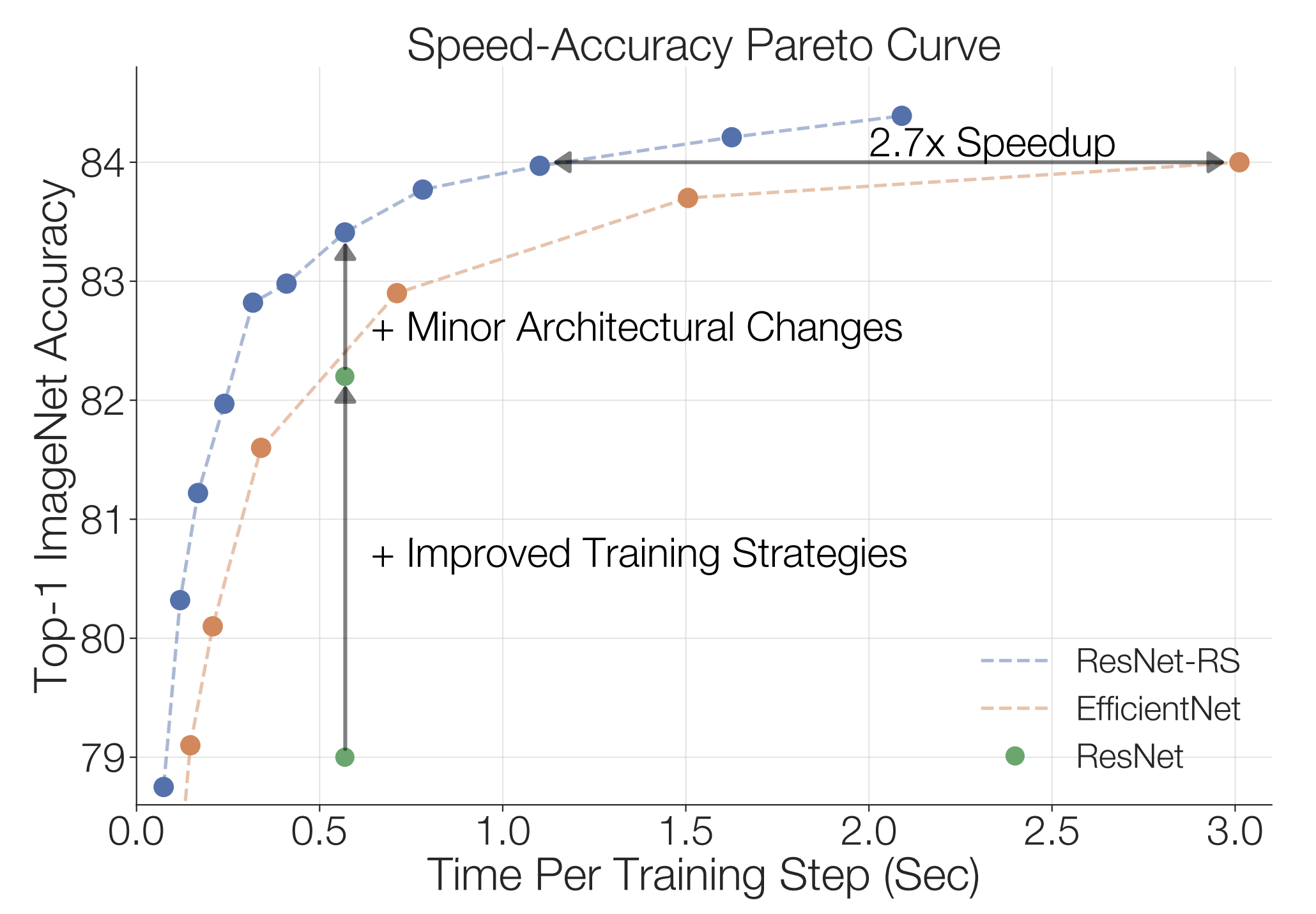
Revisiting resnets: Improved training and scaling strategies
Neurips, 2021 (Spotlight) Github / Google Cloud / Blog post Revisits training recipe and model scaling strategies for ResNets, improving ResNets to be competitive with state-of-the-art. |
|
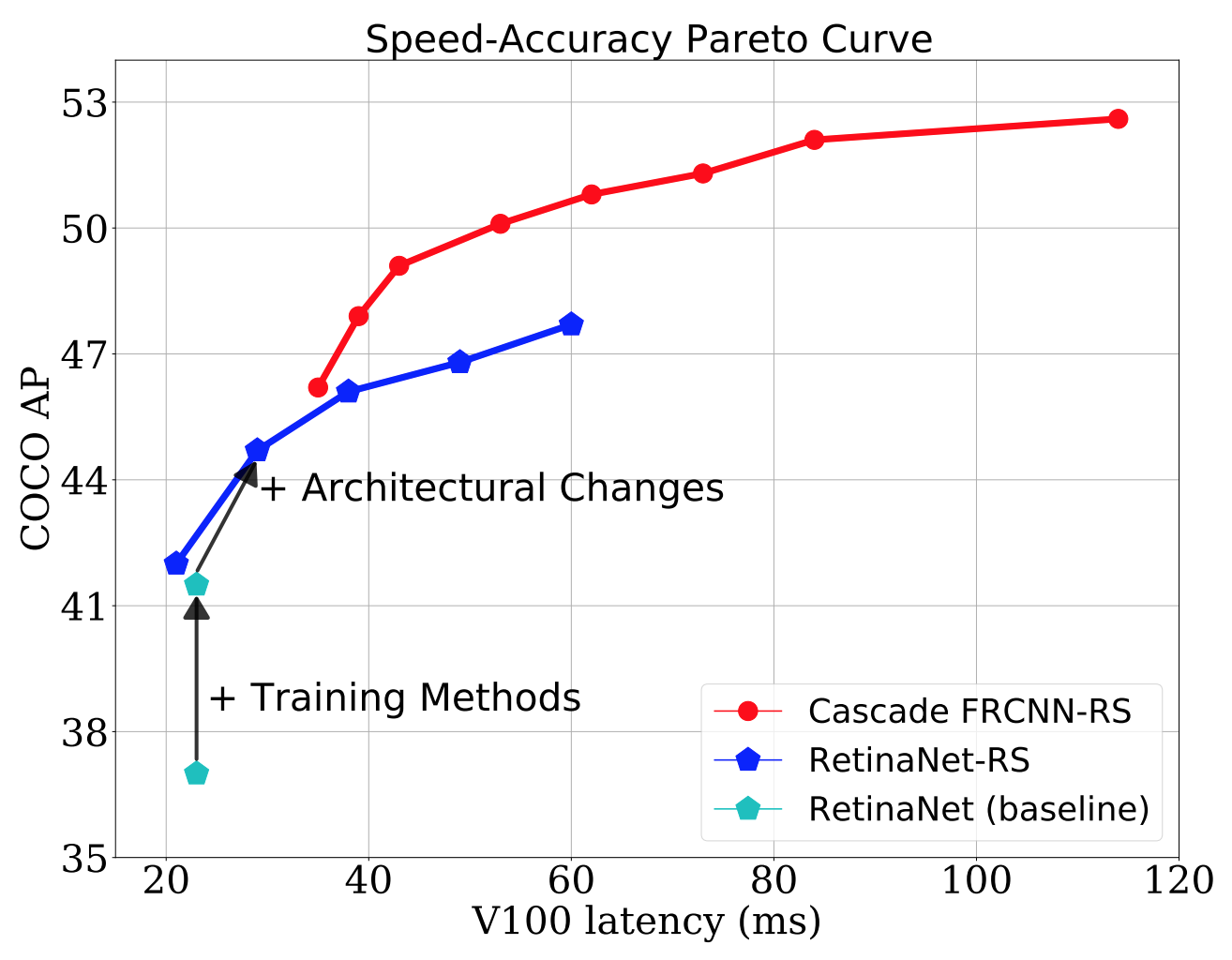
Simple training strategies and model scaling for object detection
arXiv, 2021 Github / Google Cloud Revisits training recipe and model scaling strategies for Object Detection, improving conventional object detectors, e.g. RetinaNet and Cascade R-CNN, to be competitive with state-of-the-art. |
|
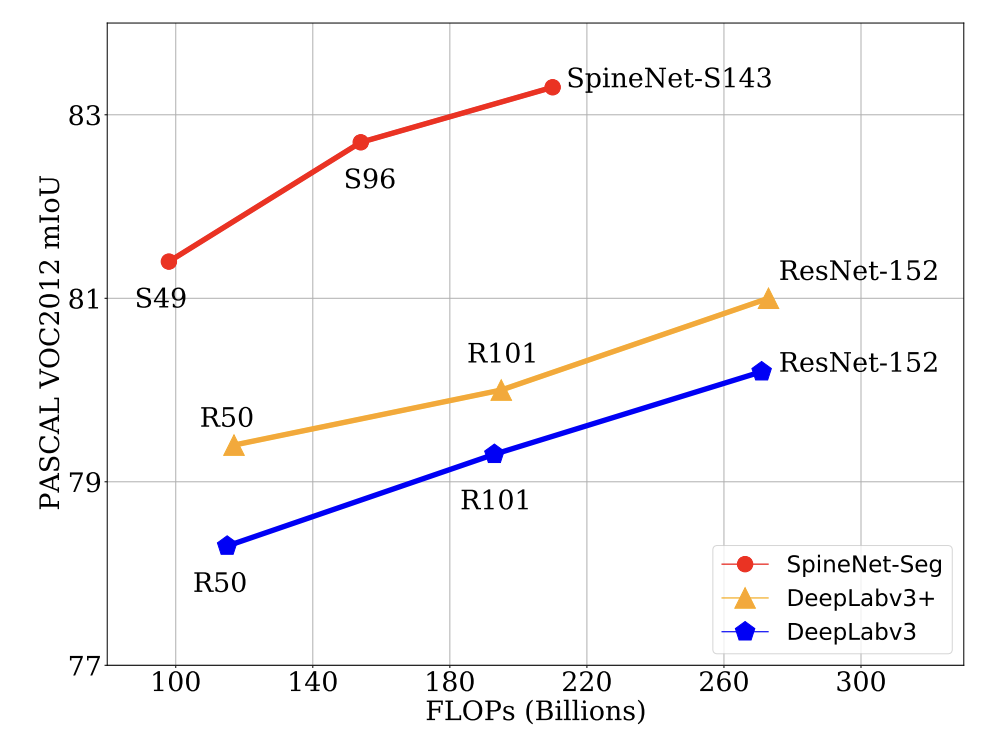
Dilated SpineNet for semantic segmentation
arXiv, 2021 Github Designs a scale-permuted backbone dilated convolutions that is learned by Neural Architecture Search (NAS) on semantic segmentation. Achieved SoTA on Cityscape semantic segmentation benchmark on 03/2021. |
|
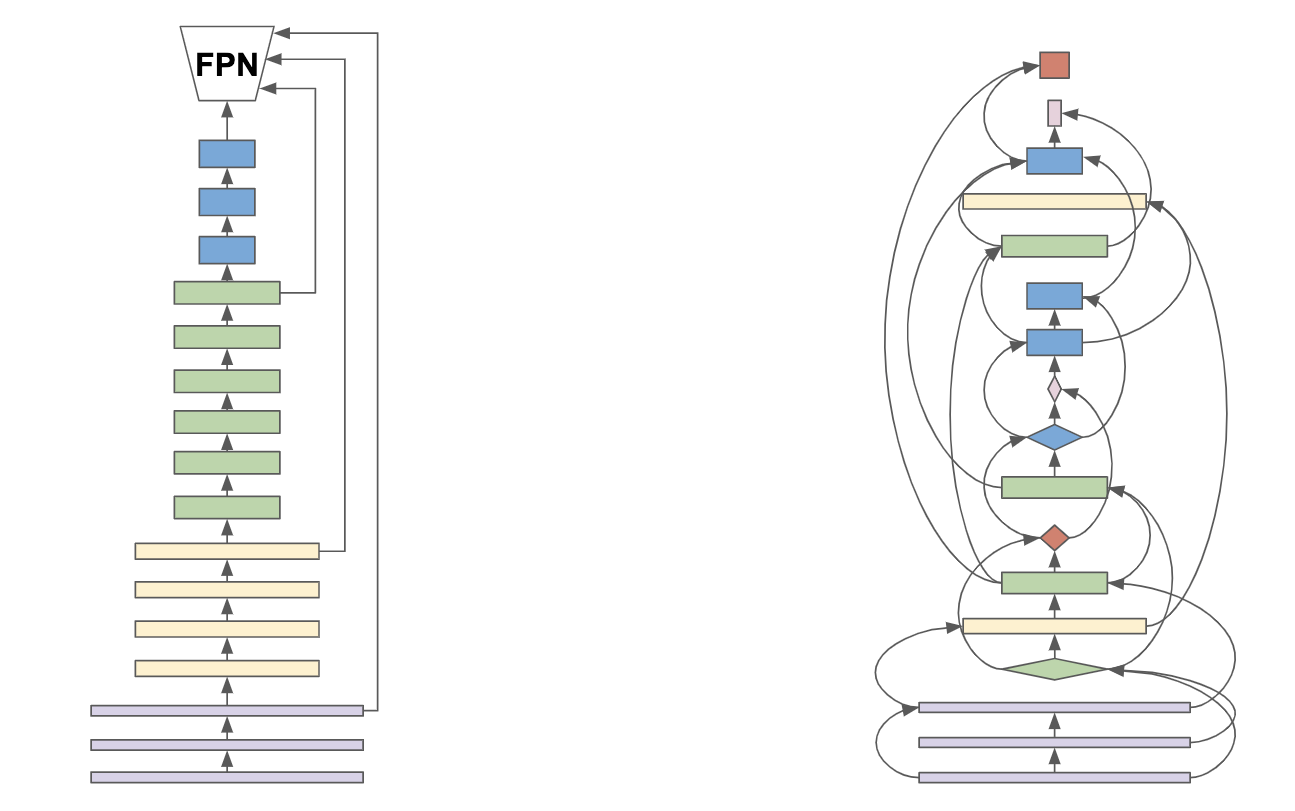
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
CVPR, 2020 Github / Yannic Kilcher's Tutorial / Google Cloud / Blog post Designs a scale-permuted backbone with intermediate features and cross-scale connections that is learned by Neural Architecture Search (NAS) on object detection. Achieved SoTA on COCO detection and segmentation benchmark on 12/2019. |
|
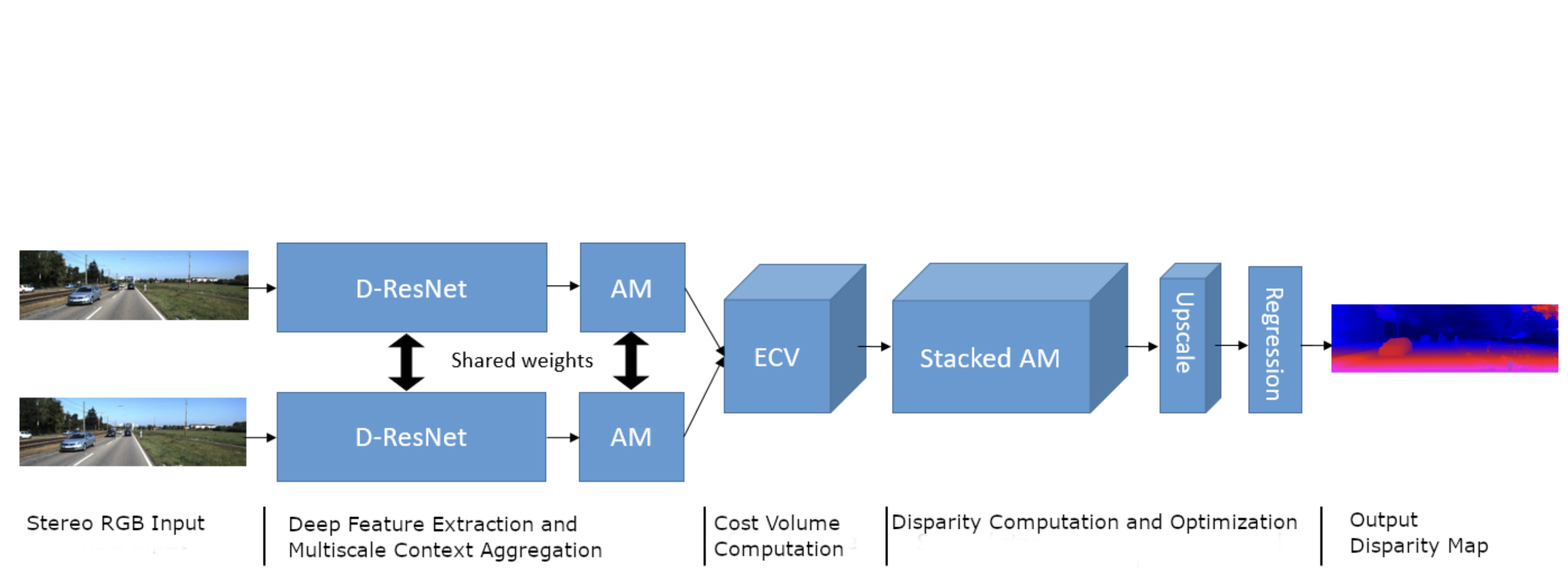
Amnet: Deep atrous multiscale stereo disparity estimation networks
ICCE, 2020 Introduces AMNet with depthwise-separable convolutions, extended cost volume, and stacked atrous multiscale network for disparity estimation. Ranked No.1 on KITTI Stereo 2015 and 2012 benchmarks on 11/2018. |
|
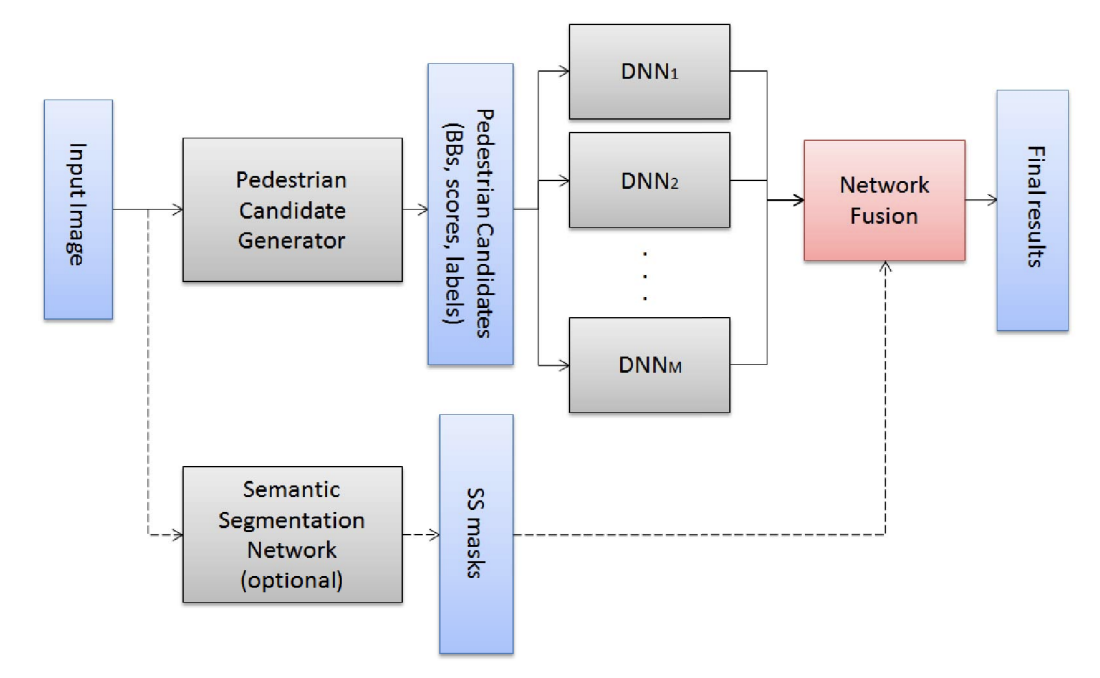
Fused DNN: A deep neural network fusion approach to fast and robust pedestrian detection
WACV, 2017 Proposes a deep neural network fusion architecture for accurate, fast and robust pedestrian detection, especially in detecting small-size and occluded pedestrians. Ranked No.1 on Caltech Pedestrian Detection benchmark on 08/2016. |
|
|